
 免费试用
免费试用
导语:很多企业想做设备状态监测,但第一步就卡住了——传感器太贵、数据看不懂、有了预警也不知道谁来处理。其实大多数企业的状态监测不需要从传感器和物联网起步,从已有的巡检数据里就能提取有价值的状态信号。本文从四个阶段拆解设备状态监测的实操路径,帮企业找到低成本切入的方式。
设备状态监测一定要上传感器吗?
这是最常见的一个误解。很多人一听到"状态监测"就想到传感器、物联网平台和实时数据大屏。实际上对于大多数非连续运转设备来说,状态监测可以从巡检数据起步,不一定需要硬件投入。
常见的做法是先用巡检表单采集设备的状态参数。比如温度、振动、运行电流、外观状态——这些数据巡检员在每次巡检时可以手动填入系统。虽然不是实时数据,但对于趋势分析来说已经很有价值。
当同一台设备的"运行温度"连续四周都在上升时,系统就能发出预警。这个预警不是传感器触发的,而是基于人工采集数据的历史趋势。对于大多数设备来说,这种"准实时"的预警已经能覆盖80%以上的故障前兆。
当然,对于高速运转、停机成本极高的核心设备,传感器的实时监测仍然有价值。但不是所有设备都需要这个级别的投入。企业应该根据设备的关键程度做分级,而不是一刀切地上硬件。
设备状态监测的两种路径对比
| 路径 | 数据来源 | 成本 | 适用场景 |
|---|---|---|---|
| 巡检数据驱动 | 人工巡检记录中的温度、振动、外观等参数 | 低,无需硬件投入 | 大多数常规设备 |
| 传感器实时监测 | 安装在设备上的温度、振动、电流传感器 | 高,需硬件采购和安装 | 核心设备、连续运转设备 |
第一步:设备建档怎么做到位?
状态监测的前提是"知道有哪些设备"。这一步听起来简单,实操中却是最常见的卡点。很多企业的设备台账不完整、信息不准确、设备编号不统一。
建议从三个动作开始。
- 一物一码:给每台需要监测的设备分配独立编号并贴二维码。二维码贴在设备本体上,巡检员扫码就能看到设备档案页,包含基本信息、巡检历史和维护记录。
- 确定参数:不同设备的关键指标不同:电机看温度和电流、泵看振动和流量、传动设备看异响和磨损。不需要一次性覆盖所有参数,先从最关键的2-3个指标开始。
- 设定基线:在新设备投入运行或老设备完成大修后,连续记录一至两周的正常运行数据作为基线。后续的监测数据都跟这个基线做对比,偏离超过阈值就触发预警。
设备建档的三个关键动作
- 一物一码:每台设备独立二维码,扫码进入档案页,打通巡检、维修和保养记录。
- 确定参数:从最关键2-3个指标起步,逐步扩展。电机先监温度电流,泵先监振动流量。
- 设定基线:新装或大修后连续记录1-2周正常数据作为基准线,后续偏离超过阈值触发预警。
第二步:巡检数据怎么"养"出趋势?
有了设备档案之后,下一步是持续积累巡检数据。这一步的核心不是"数据量大",而是"数据可比"。如果巡检员今天填"温度偏高",明天填"有点热",数据没法做趋势分析。
所以要先把检查项标准化。温度写具体数值而不是主观描述、振动用等级而不是"感觉抖"、外观状态用选项代替自由文本。标准化的数据积累三到六个月后,就可以开始做趋势分析。
举个例子:一台电机的运行温度在第一个月是65°C,第二个月是68°C,第三个月是72°C。单看每个月都在正常范围内,但趋势在持续上升。如果只看当月数据看不出来,但放到六个月的曲线上就很明显。这就是趋势的价值。
巡检频次也需要根据设备关键程度做差异化。核心设备可以每天一次、一般设备每周一次、辅助设备每月一次。频次不是越高越好,太高了巡检员会疲劳,数据质量反而下降。
第三步:预警规则怎么设才不"狼来了"?
预警机制是设备状态监测中技术含量最高也最容易出问题的一环。设得太敏感,天天报警,没人当回事;设得太宽松,真正该预警的时候又没动静。
建议从三类规则起步。
- 阈值预警:参数超过绝对上限时触发。比如电机温度超过85°C,不管什么趋势都先报警。适合安全红线类指标。
- 趋势预警:参数在连续N个周期内持续上升,即使还没超阈值也触发提醒。适合捕捉缓慢恶化趋势。
- 频率预警:某台设备在过去三个月的巡检中异常次数超过X次,说明这台设备可能进入了故障高发期,需要安排深度检修。
这三类规则配合使用,比单一阈值预警的准确率高很多。
更关键的是预警之后要有动作。预警触发后,系统自动生成一条待处理任务,推送给设备负责人。负责人处理后要回填处理结果,形成闭环。如果预警只是弹一条消息但没有人跟进,很快就会失效。
所以状态监测做到后面,核心已经不只是"看见异常",而是能不能把异常顺手推到处理动作上。用轻流设备巡检系统 这类带流程承接能力的工具,会更容易把预警、派工和回填结果连成一条线。
预警规则配置的三个层次
- 阈值预警:参数超过绝对上限(如温度>85°C)立即触发,不管趋势如何。适合安全红线类指标。
- 趋势预警:参数在连续周期内持续上升(如连续4次巡检温度递增),即使未超阈值也触发提醒。
- 频率预警:某设备在3个月内异常次数超过设定值,系统判断该设备进入故障高发期,建议深度检修。
提醒:设备状态监测的落地最大的坑不是技术选型,而是"上了系统但没人用"。巡检员不填数据、维修人员不点确认、管理者不看报表——系统再好也没用。建议在试点阶段就建立明确的考核机制:巡检完成率和数据质量纳入巡检员的绩效、预警响应时长纳入维修团队的绩效。管理配套不到位,再好的系统也跑不起来。
第四步:从预警到维修怎么形成闭环?
预警没有闭环等于白做。这条闭环包含四个节点:预警触发、任务分派、维修处理、结果验证。每个节点都不能断。

预警触发后,系统应根据设备类型和异常等级自动分派任务。比如温度异常分给电气维修组、振动异常分给机械维修组、严重异常抄送设备主管。分派规则可以提前配置,不需要每次人工判断该找谁。
维修人员接到任务后,在移动端查看设备档案和异常详情,到现场处理。处理完成后回填维修内容、更换部件和当前状态参数。系统自动将本次维修记录追加到设备档案中,并更新设备的健康评分。
以轻流 AI 无代码平台在瑞典矿山与建筑设备企业的实践为例,该企业需要大量贴合业务的流程应用来覆盖质量、设备和安全管理。通过快速搭建覆盖核心业务板块的数十个流程应用,让一线改善建议和异常处理更快闭环。
这说明设备状态监测的闭环不在技术多复杂,而在异常信息能不能快速流转到正确的人、处理结果能不能自动归档到设备档案。很多企业卡在"有数据没人看、有预警没动作",问题出在流程设计上,而不是工具能力上。

预警闭环的四个节点
- 自动分派:根据设备类型和异常等级,系统自动将任务推送给对应的维修组或负责人。
- 现场处理:维修人员在移动端查看异常详情和设备历史,到现场执行维修并拍照留证。
- 结果回填:处理完成后回填维修内容、更换部件和当前状态参数,形成完整维修记录。
- 状态更新:系统自动更新设备健康评分和保养计划,让下一次巡检有更准确的参考。
设备状态监测从试点到推广怎么推进?
不建议一次性在所有设备上铺开。比较务实的做法是先选3-5台关键设备做试点,跑通"建档—巡检—预警—维修闭环"这条完整链路,用两到三个月验证效果后再逐步扩展。
试点期间重点关注两个指标。一是预警的命中率——触发预警后有真实故障的比例。命中率太低说明规则太敏感,需要调整阈值。二是从预警到维修完成的平均时长——这个指标反映的是闭环效率。
当试点的命中率达到70%以上、闭环时长稳定在可接受范围内时,就可以考虑扩展到更多设备。扩展时不需要重新设计流程,在轻流企业数字化管理系统这类可配置平台上,复制试点设备的建档模板和预警规则,适配新设备的参数即可。
总结:设备状态监测的实操路径可以概括为四步:设备建档打基础、标准化巡检数据养趋势、分级预警规则做判断、预警到维修形成闭环。大多数企业不需要从传感器起步,从巡检数据切入就能覆盖主要设备的监测需求。瑞典矿山与建筑设备企业的实践说明,设备状态监测的价值在于异常信息能快速流转到正确的人并形成闭环,这更考验流程设计而非技术能力。

常见问题
Q1:设备状态监测和预防性维护是什么关系?
设备状态监测是预防性维护的"数据层"。状态监测负责采集和判断设备当前状态,预防性维护基于状态数据制定保养和维修计划。两者的关系可以这样理解:状态监测告诉你"设备现在怎么样了",预防性维护回答"接下来该做什么"。很多企业的系统把两者整合在同一平台上,这样监测到异常后可以自动触发维护工单,不需要人工中转。
Q2:没有IT团队能做设备状态监测吗?
如果从巡检数据路径切入(不依赖传感器和IoT平台),没有IT团队完全可以。设备管理部门的主管或熟悉流程的骨干,梳理清楚设备台账、巡检参数和预警规则后,通过可配置平台就能搭建基础的监测体系。如果需要接入传感器实时数据,那确实需要一定的技术能力,但可以先从人工采集路径做起,积累经验后再考虑硬件层面升级。
Q3:状态监测的数据积累多久才能看到效果?
一般来说,巡检数据积累三到六个月后,趋势分析开始有参考价值。前一到两个月主要用于建立设备的正常运行基线,第三个月起可以发现温度和振动等参数的缓慢偏移。第一个可见效果通常来自趋势预警——比如发现某台设备温度在持续上升,提前安排检修,避免了一次非计划停机。这种"避免了一次事故"的体感比任何报表都更有说服力。

-
设备巡检工单怎么配置和管理?异常报上来之后,谁来接才清楚
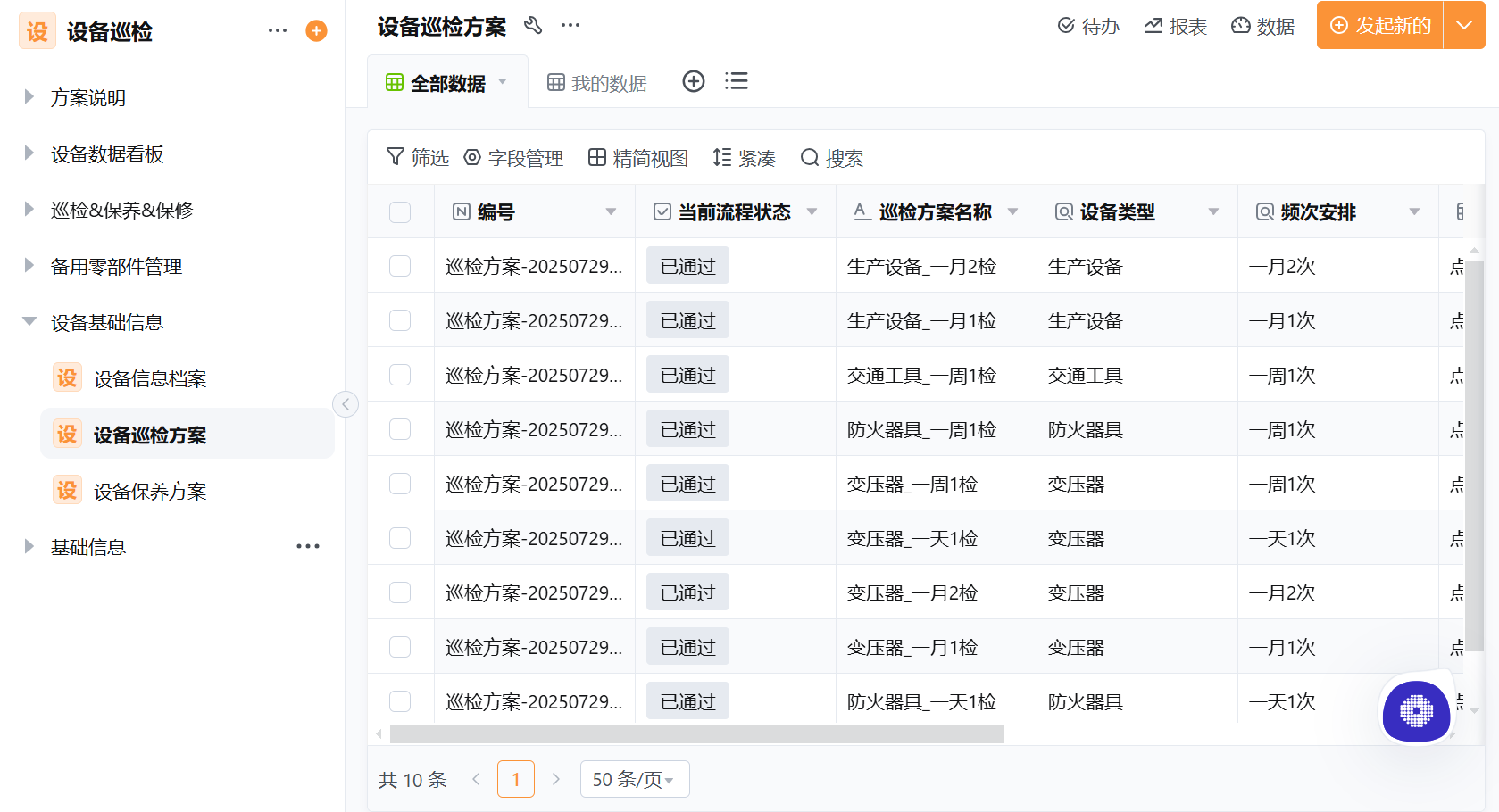 巡检工单管理是设备巡检系统从"发现问题"到"解决问题"的关键衔接环节。本文围绕巡检工单的配置与管理展开,覆盖巡检工单自动生成、巡检任务派发、巡检工单流程配置、巡检计划管理、巡检路线管理、巡检工单闭环等核心功能。企业从最初的手动派单到系统自动派发、从口头传达到流程驱动、从无据可查到全链路追溯,每一步都涉及流程配置……2026-07-31
巡检工单管理是设备巡检系统从"发现问题"到"解决问题"的关键衔接环节。本文围绕巡检工单的配置与管理展开,覆盖巡检工单自动生成、巡检任务派发、巡检工单流程配置、巡检计划管理、巡检路线管理、巡检工单闭环等核心功能。企业从最初的手动派单到系统自动派发、从口头传达到流程驱动、从无据可查到全链路追溯,每一步都涉及流程配置……2026-07-31 -
设备保养计划怎么制定和执行?让周期跟着状态走,维修才不会总救火
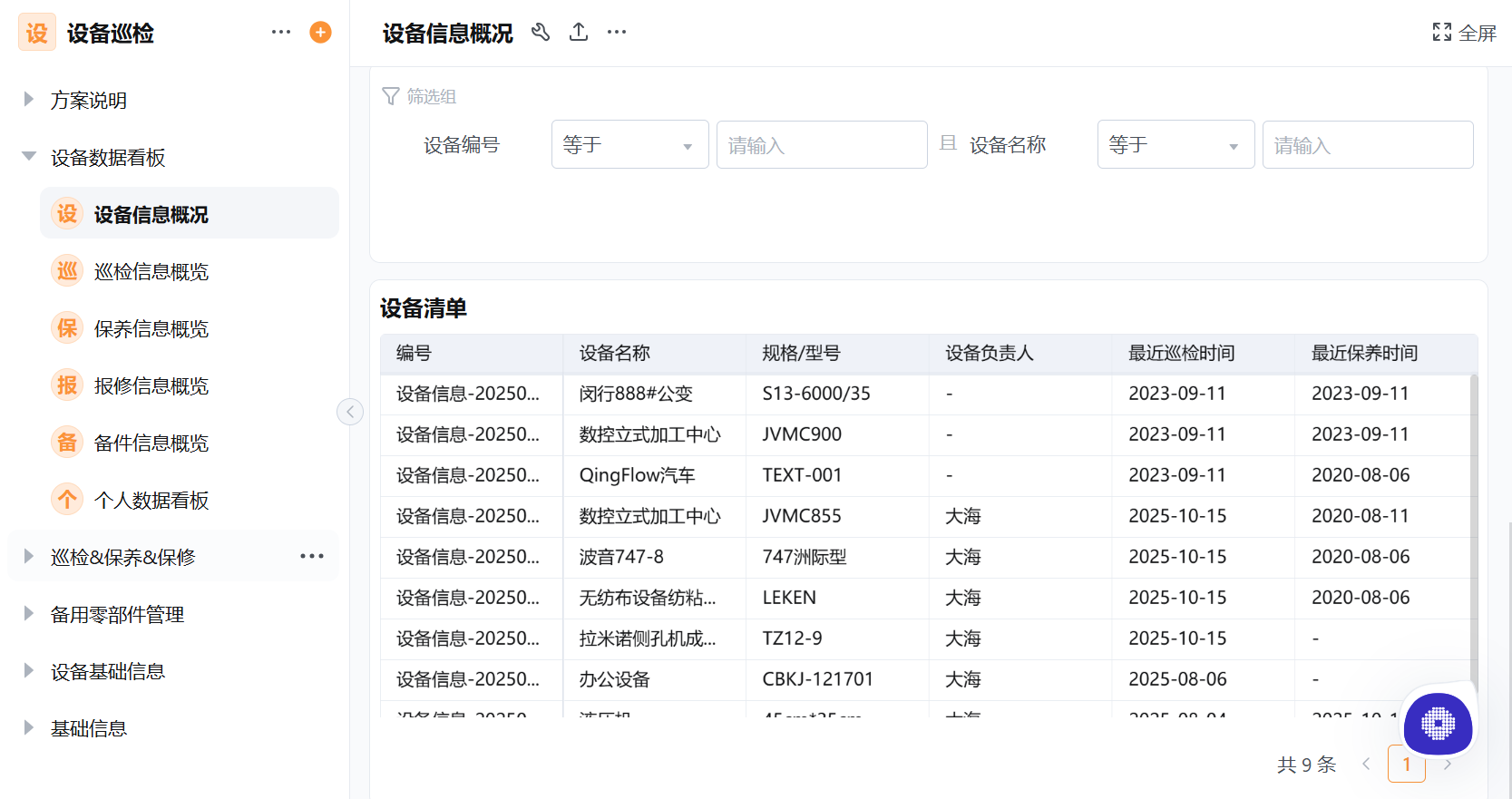 设备维护保养管理是设备巡检系统中容易被低估但直接影响设备寿命和故障率的核心模块。本文围绕设备保养计划制定、保养周期设置、保养工单自动生成、保养执行记录和保养效果分析等功能展开,帮助企业理解如何从"坏了再修"转向"按计划保养"的预防性维护模式。结合轻流AI无代码平台在设备维护管理系统中的实践,本文覆盖设备保养计划……2026-07-31
设备维护保养管理是设备巡检系统中容易被低估但直接影响设备寿命和故障率的核心模块。本文围绕设备保养计划制定、保养周期设置、保养工单自动生成、保养执行记录和保养效果分析等功能展开,帮助企业理解如何从"坏了再修"转向"按计划保养"的预防性维护模式。结合轻流AI无代码平台在设备维护管理系统中的实践,本文覆盖设备保养计划……2026-07-31 -
矿业设备巡检系统怎么落地?AI让隐患整改不只停在矿山现场
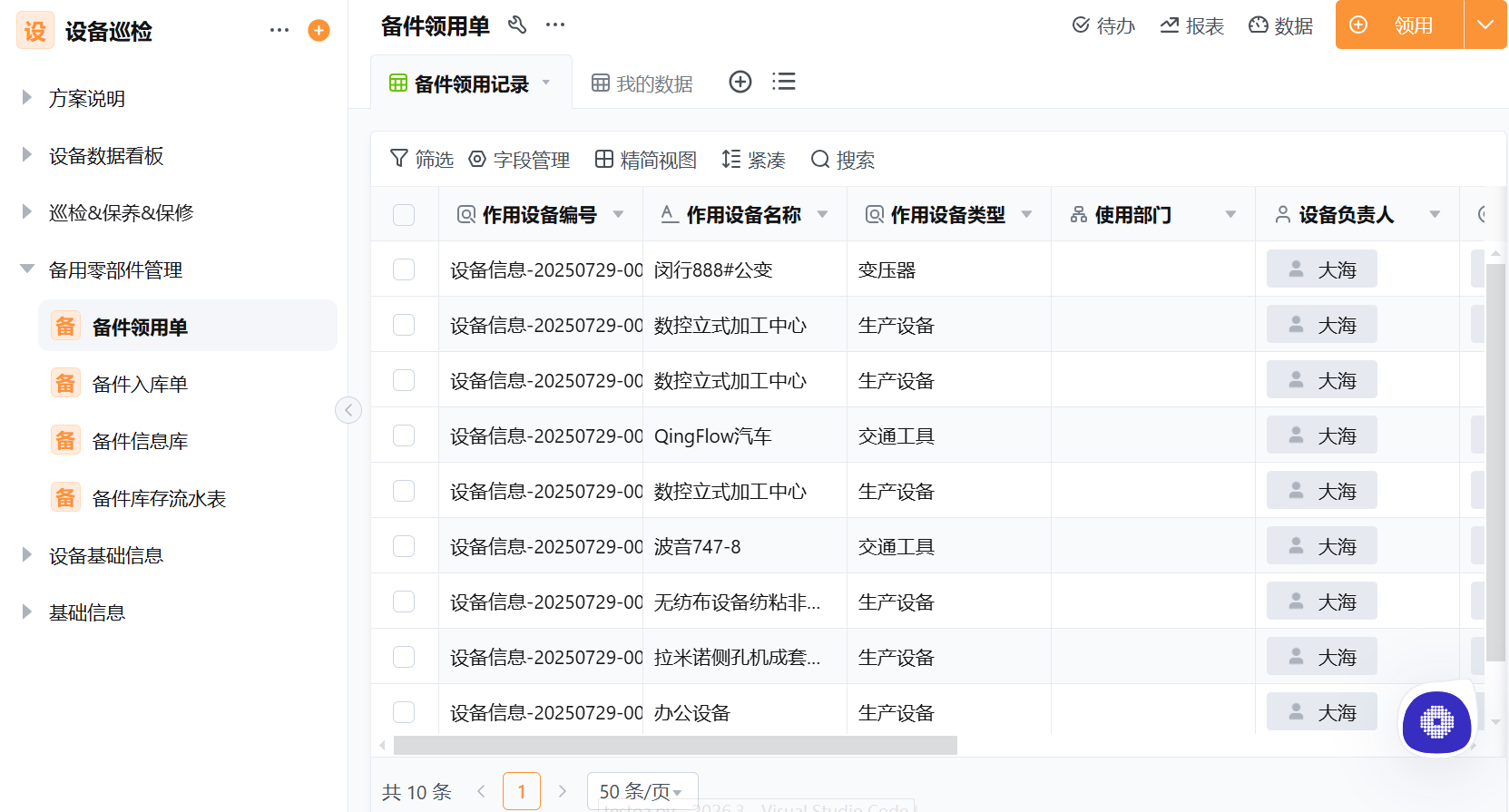 矿业设备巡检面临设备分散、环境恶劣、安全合规要求高、纸质记录难追溯等多重挑战。本文聚焦矿山企业设备巡检管理的行业特性,围绕设备巡检系统在矿业场景中的落地方式展开,覆盖矿山设备巡检、设备安全巡检、矿业设备管理、高危行业设备巡检、设备巡检AI预警、矿山设备保养等关键场景。结合轻流AI无代码平台在阳山温榜山矿业的实践……2026-07-31
矿业设备巡检面临设备分散、环境恶劣、安全合规要求高、纸质记录难追溯等多重挑战。本文聚焦矿山企业设备巡检管理的行业特性,围绕设备巡检系统在矿业场景中的落地方式展开,覆盖矿山设备巡检、设备安全巡检、矿业设备管理、高危行业设备巡检、设备巡检AI预警、矿山设备保养等关键场景。结合轻流AI无代码平台在阳山温榜山矿业的实践……2026-07-31 -
AI设备巡检怎么沉淀经验和辅助决策?让老师傅的处理办法不再跟着人走
 AI在设备巡检系统中的应用不只是自动预警,更重要的价值在于辅助经验沉淀和决策支持。本文围绕AI设备巡检系统在知识管理方面的功能展开,覆盖AI设备异常判断、巡检知识库建设、AI巡检经验沉淀、设备故障知识管理、AI巡检建议生成、智能巡检辅助决策等核心场景。传统巡检中,最有价值的故障处理经验往往只存在于老员工的脑子里……2026-07-31
AI在设备巡检系统中的应用不只是自动预警,更重要的价值在于辅助经验沉淀和决策支持。本文围绕AI设备巡检系统在知识管理方面的功能展开,覆盖AI设备异常判断、巡检知识库建设、AI巡检经验沉淀、设备故障知识管理、AI巡检建议生成、智能巡检辅助决策等核心场景。传统巡检中,最有价值的故障处理经验往往只存在于老员工的脑子里……2026-07-31 -
设备二维码巡检怎么落地?每台设备有了身份,现场记录才不再断线
 扫码巡检是设备巡检系统中最直观的落地方式之一,通过为每台设备生成唯一二维码并粘贴在现场,巡检人员扫码即可查看设备档案、填写巡检表单、上传现场照片、上报异常。本文围绕二维码设备巡检的落地流程展开,覆盖设备二维码制作、扫码查看设备档案、巡检记录电子化、扫码巡检流程配置、一物一码设备管理、二维码巡检系统选型等关键场景……2026-07-31
扫码巡检是设备巡检系统中最直观的落地方式之一,通过为每台设备生成唯一二维码并粘贴在现场,巡检人员扫码即可查看设备档案、填写巡检表单、上传现场照片、上报异常。本文围绕二维码设备巡检的落地流程展开,覆盖设备二维码制作、扫码查看设备档案、巡检记录电子化、扫码巡检流程配置、一物一码设备管理、二维码巡检系统选型等关键场景……2026-07-31 -
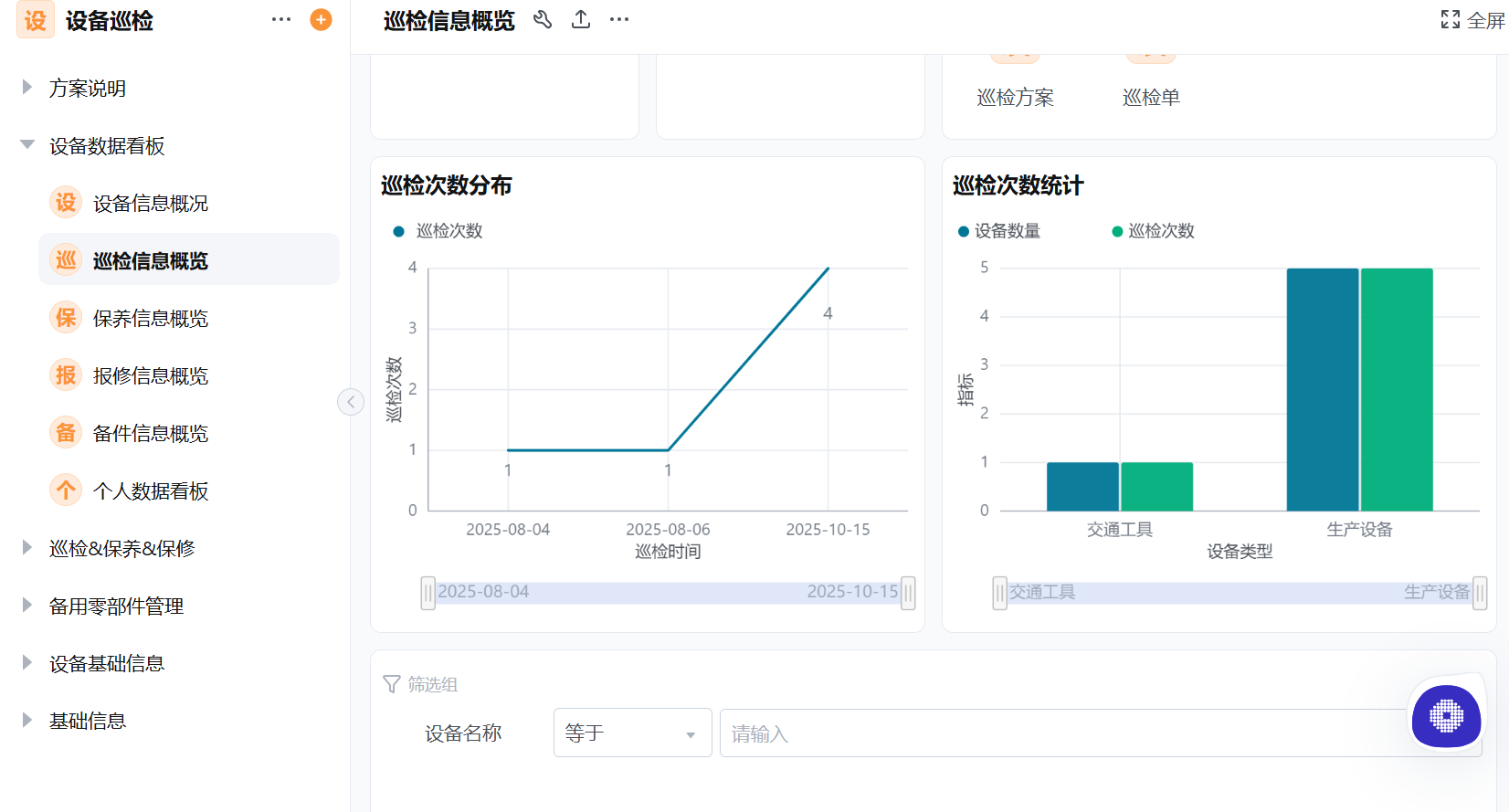
设备巡检落地五阶段,台账整理之后为什么先上小范围试点
 设备巡检系统从规划到上线,最难的往往不是技术选型,而是"怎么让一线人员真正用起来"。2026年很多企业发现,巡检系统上线失败的原因不是功能不够,而是实施路径错了——要么一步到位追求全覆盖导致推进困难,要么只做电子化不做流程优化导致系统变成"电子版纸质表"。本文从设备台账整理、巡检流程设计、试点运行、全面推广和持……2026-07-30
设备巡检系统从规划到上线,最难的往往不是技术选型,而是"怎么让一线人员真正用起来"。2026年很多企业发现,巡检系统上线失败的原因不是功能不够,而是实施路径错了——要么一步到位追求全覆盖导致推进困难,要么只做电子化不做流程优化导致系统变成"电子版纸质表"。本文从设备台账整理、巡检流程设计、试点运行、全面推广和持……2026-07-30 -
异常上报后没人接,设备巡检工单怎样从派发走到验收
 设备巡检的价值在于"发现异常之后怎么办"。很多企业巡检做得勤,但异常上报靠微信群、维修派单靠打电话、处理结果靠口头反馈,巡检和维修之间始终是断层的。本文围绕巡检异常转维修工单一体化,从流程打通、工单自动派发、移动端协同、维修闭环追溯四个维度展开,结合超威集团等制造企业的真实实践,说明如何通过轻流AI无代码平台把……2026-07-30
设备巡检的价值在于"发现异常之后怎么办"。很多企业巡检做得勤,但异常上报靠微信群、维修派单靠打电话、处理结果靠口头反馈,巡检和维修之间始终是断层的。本文围绕巡检异常转维修工单一体化,从流程打通、工单自动派发、移动端协同、维修闭环追溯四个维度展开,结合超威集团等制造企业的真实实践,说明如何通过轻流AI无代码平台把……2026-07-30 -
无代码设备巡检和传统开发怎么选?2026年设备巡检系统搭建方式对比评测
 设备巡检系统的搭建方式正在成为企业选型时的关键决策变量。传统定制开发周期长、成本高但灵活度大,成品SaaS软件上线快但适配性差,无代码平台则提供了第三种路径:既能快速启动,又能按需调整。2026年越来越多的企业开始认真比较这三种搭建方式的优劣,而非简单选择"最便宜"或"最知名"的方案。本文从开发周期、成本结构……2026-07-30
设备巡检系统的搭建方式正在成为企业选型时的关键决策变量。传统定制开发周期长、成本高但灵活度大,成品SaaS软件上线快但适配性差,无代码平台则提供了第三种路径:既能快速启动,又能按需调整。2026年越来越多的企业开始认真比较这三种搭建方式的优劣,而非简单选择"最便宜"或"最知名"的方案。本文从开发周期、成本结构……2026-07-30 -
巡检报表不只报次数:故障、点位、响应、备件四组数据怎么看
设备巡检产生的数据如果只停留在"本月巡检了多少次、发现多少异常"的统计层面,其管理价值就被严重低估了。2026年越来越多企业开始关注巡检数据的深度分析和可视化呈现:哪些设备故障率最高、哪些巡检点位异常重复率最高、维修响应时间是否达标、备件消耗是否合理。本文从设备巡检数据分析的实际场景出发,拆解报表设计、异常趋势……2026-07-30 -
变电站、线路、场站分得很开,电力设备巡检系统要先管住什么
 电力行业的设备巡检与一般制造业有本质区别:巡检范围覆盖变电站、输电线路、配电设备等广域分布资产,对巡检频次、数据准确性、异常响应速度和安全合规的要求远超普通工厂场景。2026年随着电力行业数字化转型加速,越来越多的发电企业、电网公司和新能源场站开始从传统人工巡检模式向智能化巡检系统过渡。本文从电力巡检的特殊场景……2026-07-30
电力行业的设备巡检与一般制造业有本质区别:巡检范围覆盖变电站、输电线路、配电设备等广域分布资产,对巡检频次、数据准确性、异常响应速度和安全合规的要求远超普通工厂场景。2026年随着电力行业数字化转型加速,越来越多的发电企业、电网公司和新能源场站开始从传统人工巡检模式向智能化巡检系统过渡。本文从电力巡检的特殊场景……2026-07-30

轻客CRM

轻银费控
生产管理

项目管理


